Hashing
Hashing involves generating a unique identifier for a piece of data by applying a hash function to an input (or “key”). The resulting hash code is then used to quickly store or retrieve the data from a hash table. Essentially, hashing creates a distinct label for each piece of data, and the hash code helps point to the location in memory where the data is stored, enabling fast access.
Hash Tables
A hash table is a data structure that stores data in key-value pairs. The key acts as a unique identifier, while the value is the associated data. Hash tables use the hash code to map the key to a specific location in memory, making the process of accessing or updating data efficient. The goal of a hash table is to offer fast access to data by using a key to reference its corresponding value.
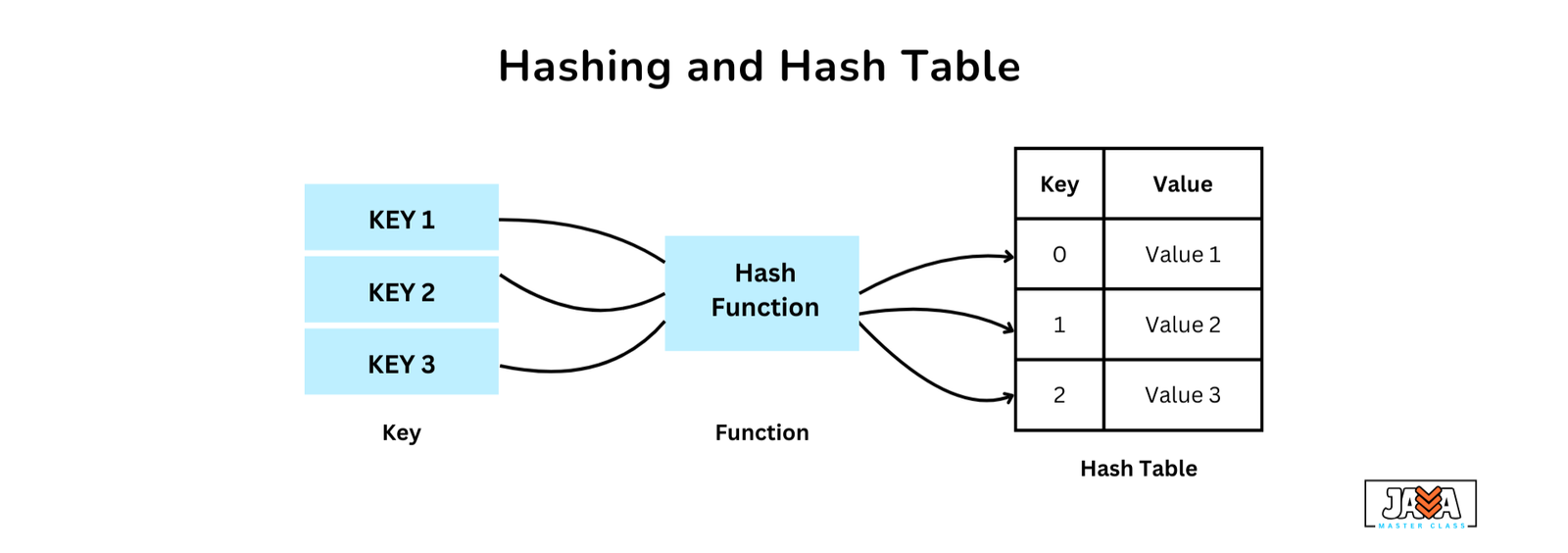
Hashing with HashMap
In Java, the HashMap class is the most commonly used implementation of a hash table. It stores data as key-value pairs and leverages hashing to quickly retrieve the associated value for a given key. Here’s how it works:
- Hashing: When adding a key-value pair to a
HashMap, Java calculates the hash code of the key (via thehashCode()method) to determine where the data should be stored in memory. - Bucket Assignment: The hash code is used to assign the key-value pair to a “bucket” or “slot” in the hash table.
- Handling Collisions: If two keys generate the same hash code (a “collision”), Java handles it through chaining (storing multiple values in the same bucket) or open addressing (finding an alternative bucket).
Declaration & Initialization
In Java, you can declare a hash table using the HashMap or Hashtable classes from the java.util package.
|
1 2 3 4 5 6 7 |
// Using HashMap (Recommended for most use cases) import java.util.HashMap; HashMap<Integer, String> hashMap = new HashMap<>(); // Using Hashtable (older, synchronized version) import java.util.Hashtable; Hashtable<Integer, String> hashTable = new Hashtable<>(); |
You can also initialize with a specific capacity and load factor to control resizing behavior:
|
1 |
HashMap<Integer, String> hashMap = new HashMap<>(16, 0.75f); // Initial capacity 16, load factor 0.75 |
Basic Operations
Insertion: Add a new key-value pair.
|
1 2 |
hashMap.put(1, "One"); hashMap.put(2, "Two"); |
Deletion: Remove a key-value pair by key.
|
1 |
hashMap.remove(1); // Removes the entry with key '1' |
Traversal: Iterate through all key-value pairs.
|
1 2 3 |
for (Map.Entry<Integer, String> entry : hashMap.entrySet()) { System.out.println(entry.getKey() + ": " + entry.getValue()); } |
Example
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import java.util.HashMap; public class HashMapExample { public static void main(String[] args) { // Create a new HashMap HashMap<String, Integer> map = new HashMap<>(); // Add some key-value pairs map.put("Apple", 3); map.put("Banana", 5); map.put("Orange", 2); // Retrieve a value by key System.out.println("Apple: " + map.get("Apple")); // Output: Apple: 3 // Check if a key exists if (map.containsKey("Banana")) { System.out.println("Banana exists in the map!"); } // Remove a key-value pair map.remove("Orange"); // Print the entire map System.out.println(map); } } //Output Apple: 3 Banana exists in the map! {Apple=3, Banana=5} |
In the above example:
- A
HashMapstores fruit names as keys and their quantities as values. - Three key-value pairs are inserted using the
put()method. - The value for the “Apple” key is retrieved using the
get()method. - The presence of the “Banana” key is confirmed, and the “Orange” entry is removed using the
remove()method.
Advantages & Disadvantages
| Advantages | Disadvantages |
|---|---|
| Fast Access: Provides O(1) time complexity for search, insertion, and deletion (on average). | Collisions: Collisions can reduce performance and need to be handled efficiently. |
| Efficient Memory Use: Hash tables are space-efficient, especially with open addressing. | Order is not preserved: Hash tables do not guarantee any specific order of elements. |
| Supports a wide range of data types: Keys can be of any data type, as long as they are hashable. | Complexity: The underlying implementation can be complex, especially with collision resolution strategies. |
Real World Examples
- Cache Systems: Hash tables are often used in caching systems where fast lookups are necessary. For example, the LRU Cache (Least Recently Used) uses hash tables to store and retrieve the most recently used items.
- Database Indexing: Many databases use hashing techniques to create indexes for fast data retrieval.
- Dictionary and Spell Checkers: A dictionary that stores words with their meanings can be implemented using a hash table, allowing quick lookups of words.
- Routing Tables in Networking: Hash tables are used to quickly find routes in a network based on destination IP addresses.

